“Stepwise” involves the development of statistical and visualization results through a series of LLM prompts.
Using a stepwise analysis approach lets you add features in an orderly way, especially as you better understand about your data.
Entering the Data & Guidelines
Prompt
I have provided a file with important guidelines which must be followed in creating R code.
I have some test data, so please call the data source “test data”. The study is called “Apple Tree Planting”.
Each harvest, the yield is measured by the total number of buckets harvested. There are two tree arrangements, each one covering the same land area. In one arrangement (“traditional”), trees are spaced out like traditional orchards. The other arrangement (“hedges”) has trees planted in hedges. There are yield data for a period of five harvests. The hedge trees had 57, 34, 68, 52, and 71 buckets. The traditional orchard had 61, 32, 74, 48, and 78 buckets.
I would like R code that shows the data entered in straightforward way and produces a formal data table. Please double check the use of the specifications.
Response
Certainly! I’ll create R code that follows the guidelines you’ve provided, including those from the input and table guideline documents. I’ll set up the data input, create a formal table using the gt package, and ensure all specifications are met. Let’s go through this step-by-step:
I’ve created R code that follows the guidelines provided. Here’s a breakdown of what the code does:
It starts with the error and warning suppression as specified.
The necessary libraries are loaded: tidyverse, readr, and gt.
The read_csv option is set to suppress column type messages.
The data is input using read_csv, with column names and aligned data for easy viewing.
The data is written to a CSV file for later use.
Table title and data source variables are initialized.
A gt table is created with the following features:
The table header includes the title.
A source note is added.
Cell text is aligned to the top.
Harvest columns are formatted as integers.
Column labels are renamed for clarity.
A footnote is added to indicate the units (buckets) for the harvest columns.
The table is output without using print().
This code adheres to the guidelines by using double hash marks for comments, describing each action, and following the formatting and structure rules provided in the guideline documents. The data source is set to “test data” as requested, and the study name “Apple Tree Planting” is incorporated into the table title.
Is there anything you’d like me to modify or expand upon in this code?
Show the code
## Use the package for the read_csv function and table creationlibrary(tidyverse)library(readr)library(gt)## Set read_csv function option to suppress warning messagesoptions(readr.show_col_types =FALSE)## Data inputdata<-read_csv(col_names =TRUE, file ="arrangement, harvest1, harvest2, harvest3, harvest4, harvest5 hedges, 57, 34, 68, 52, 71 traditional, 61, 32, 74, 48, 78")## Write the data to a CSV file for later usewrite_csv(data, "apple_tree_planting_data.csv")## Initialize the identification informationtable_title<-"Apple Tree Planting Study: Yield Comparison"data_source<-"test data"## Create the tabletable<-gt(data)%>%tab_header( title =table_title)%>%tab_source_note( source_note =paste0("Source: ", data_source))%>%tab_style( style =cell_text(v_align ="top"), locations =cells_body())%>%fmt_integer( columns =starts_with("harvest"))%>%cols_label( arrangement ="Tree Arrangement", harvest1 ="Harvest 1", harvest2 ="Harvest 2", harvest3 ="Harvest 3", harvest4 ="Harvest 4", harvest5 ="Harvest 5")%>%tab_footnote( footnote ="buckets", locations =cells_column_labels(columns =starts_with("harvest")))## Output the tabletable
Apple Tree Planting Study: Yield Comparison
Tree Arrangement
Harvest 11
Harvest 21
Harvest 31
Harvest 41
Harvest 51
hedges
57
34
68
52
71
traditional
61
32
74
48
78
Source: test data
1 buckets
Adding a Bar Chart
Prompt
I like this result and want to build on it using the saved data file.
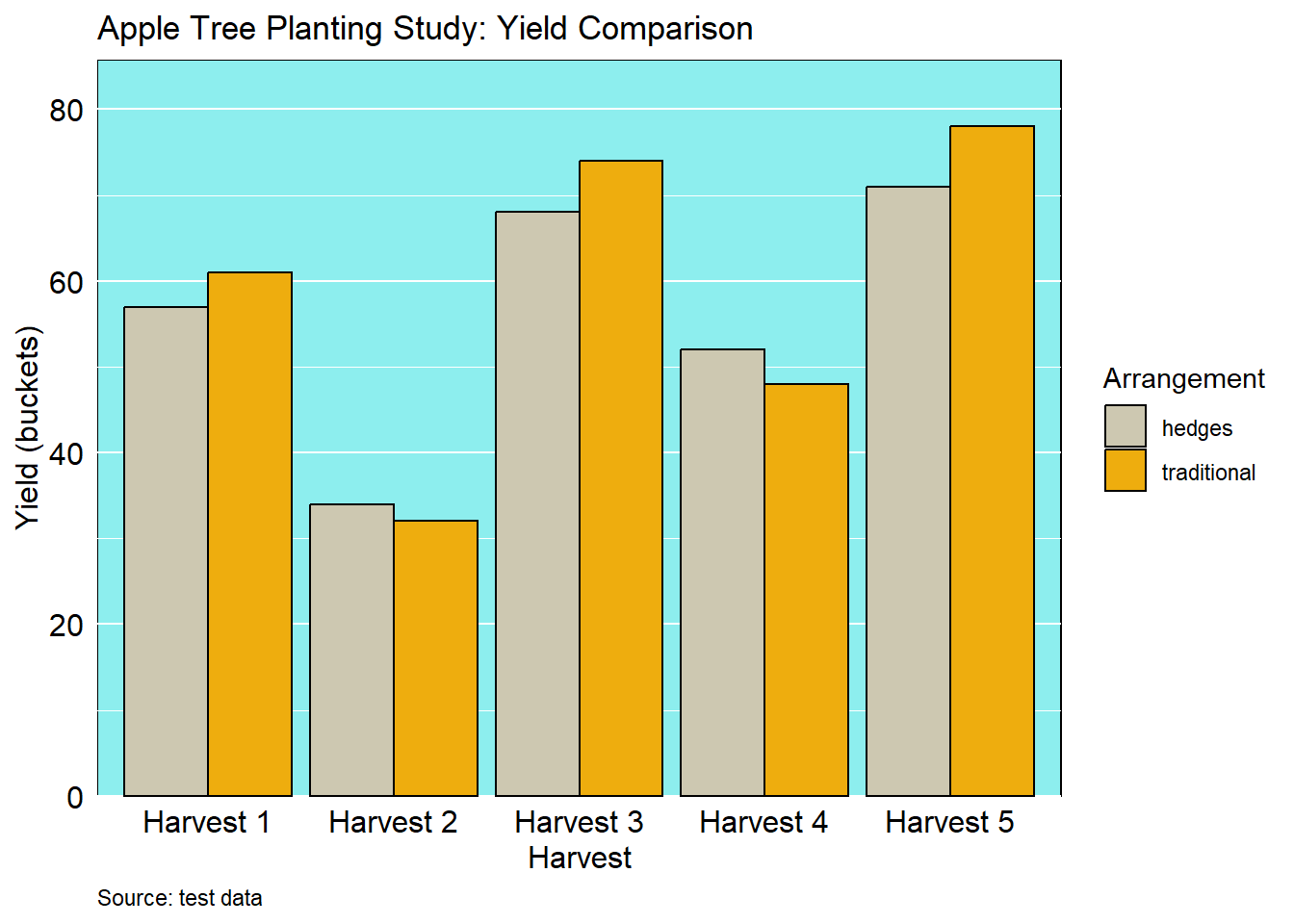
Can you add a chart that shows pairs of bars (hedge, traditional) for each of the harvests?
Response
Certainly! I’ll create a bar chart using the saved data file, showing pairs of bars for hedge and traditional arrangements for each harvest. I’ll use the ggplot2 package (part of tidyverse) to create this chart, following the guidelines provided in the bar chart document.
I’ve updated the R code to include the creation of a bar chart as requested. Here’s a breakdown of the new additions:
The code now reads the previously saved CSV file instead of inputting the data directly.
The data is reshaped into a long format suitable for ggplot2 using pivot_longer().
A bar chart is created using ggplot2 with the following features:
Pairs of bars (hedge and traditional) for each harvest.
Black outlines for each bar.
Fill colors: “cornsilk3” for hedges and “darkgoldenrod2” for traditional, as per the guidelines.
Panel background color set to “darkslategray2”.
Axis labels and title in black, size 12.
Y-axis grid lines (white color for better visibility on the dark background).
No X-axis grid lines, but tick marks are present.
Y-axis starts at zero with a small extension at the top.
Source information added as a caption.
The code follows all the specified guidelines for bar chart formatting. The table creation code remains the same as before.
Is there anything you’d like me to modify or explain further about this updated code?
Show the code
## Use the packages for data manipulation, visualization, and table creationlibrary(tidyverse)library(readr)library(gt)## Set read_csv function option to suppress warning messagesoptions(readr.show_col_types =FALSE)## Read the previously saved datadata<-read_csv("apple_tree_planting_data.csv")## Reshape the data for plottingdata_long<-data%>%pivot_longer(cols =starts_with("harvest"), names_to ="harvest", values_to ="yield")%>%mutate(harvest =factor(harvest, levels =c("harvest1", "harvest2", "harvest3", "harvest4", "harvest5"), labels =c("Harvest 1", "Harvest 2", "Harvest 3", "Harvest 4", "Harvest 5")))## Create the bar chartchart<-ggplot(data_long, aes(x =harvest, y =yield, fill =arrangement))+geom_bar(stat ="identity", position =position_dodge(width =0.9), color ="black")+scale_fill_manual(values =c("hedges"="cornsilk3", "traditional"="darkgoldenrod2"))+labs(title ="Apple Tree Planting Study: Yield Comparison", x ="Harvest", y ="Yield (buckets)", fill ="Arrangement", caption ="Source: test data")+theme_minimal()+theme( panel.background =element_rect(fill ="darkslategray2"), axis.text =element_text(color ="black", size =12), axis.title =element_text(color ="black", size =12), panel.grid.major.x =element_blank(), panel.grid.minor.x =element_blank(), panel.grid.major.y =element_line(color ="white"), panel.grid.minor.y =element_line(color ="white"), plot.caption =element_text(hjust =0))+scale_y_continuous(expand =expansion(mult =c(0, 0.1)))## Display the chartprint(chart)
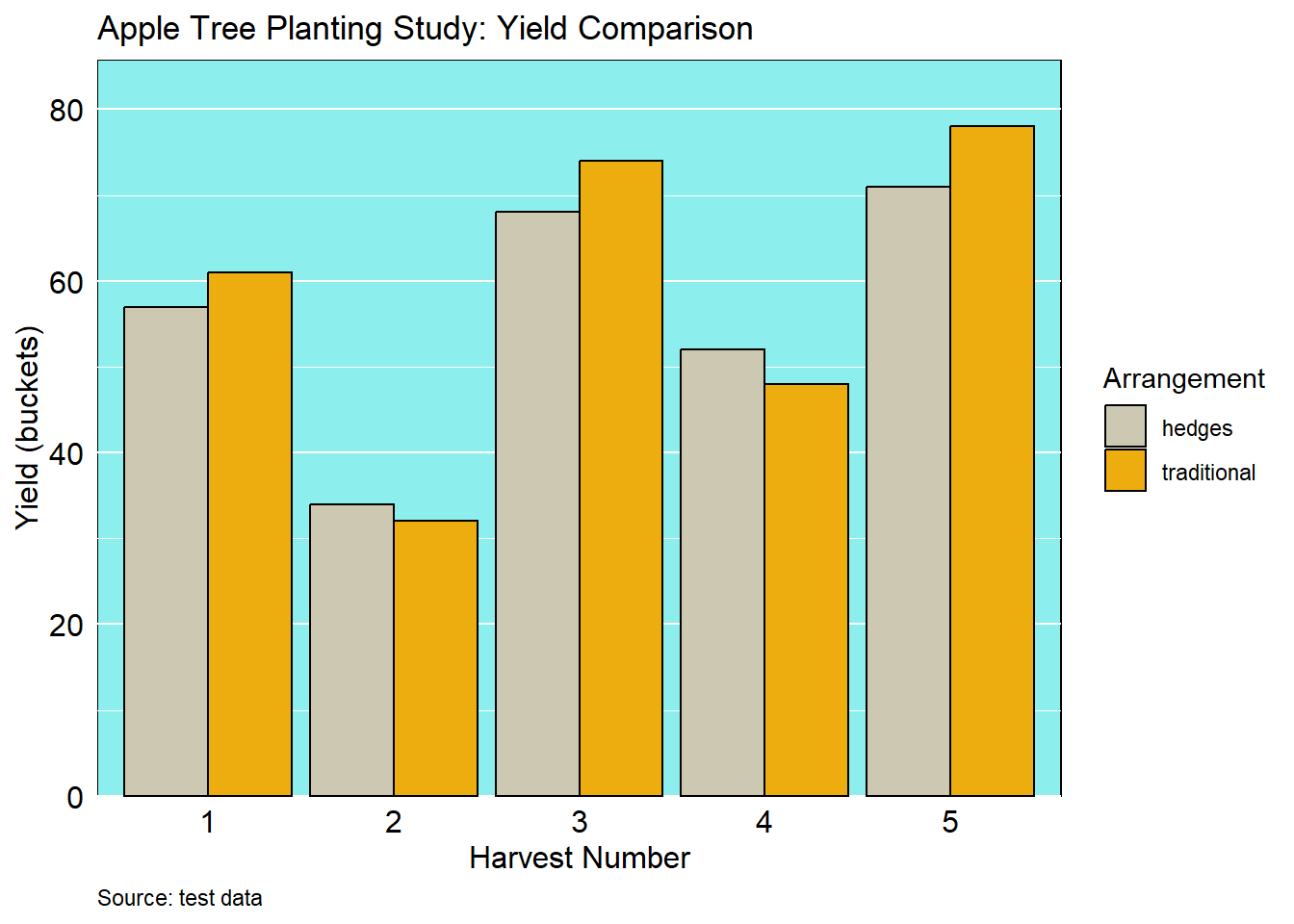
That’s good. But can you use only the number of each harvest in the bar chart x axis.
Response
Certainly! I’ll modify the bar chart to use only the harvest numbers on the x-axis instead of the full “Harvest X” labels. Here’s the updated code for the chart:
Here are the key changes I’ve made to the code:
In the data reshaping step, I’ve added a new column harvest_number that extracts just the numeric part from the harvest names:
In the ggplot code, I’ve changed the x-axis to use factor(harvest_number) instead of harvest:
ggplot(data_long, aes(x =factor(harvest_number), y = yield, fill = arrangement)) +
I’ve updated the x-axis label to “Harvest Number” to reflect this change:
labs(title ="Apple Tree Planting Study: Yield Comparison", x ="Harvest Number", y ="Yield (buckets)", fill ="Arrangement", caption ="Source: test data")
These modifications will result in a bar chart that uses only the harvest numbers (1, 2, 3, 4, 5) on the x-axis, as requested. The rest of the chart formatting and the table creation code remain the same as before.
Is there anything else you’d like me to adjust or explain about this updated code?
Show the code
## Use the packages for data manipulation, visualization, and table creationlibrary(tidyverse)library(readr)library(gt)## Set read_csv function option to suppress warning messagesoptions(readr.show_col_types =FALSE)## Read the previously saved datadata<-read_csv("apple_tree_planting_data.csv")## Reshape the data for plottingdata_long<-data%>%pivot_longer(cols =starts_with("harvest"), names_to ="harvest", values_to ="yield")%>%mutate(harvest_number =as.integer(str_extract(harvest, "\\d+")))## Create the bar chartchart<-ggplot(data_long, aes(x =factor(harvest_number), y =yield, fill =arrangement))+geom_bar(stat ="identity", position =position_dodge(width =0.9), color ="black")+scale_fill_manual(values =c("hedges"="cornsilk3", "traditional"="darkgoldenrod2"))+labs(title ="Apple Tree Planting Study: Yield Comparison", x ="Harvest Number", y ="Yield (buckets)", fill ="Arrangement", caption ="Source: test data")+theme_minimal()+theme( panel.background =element_rect(fill ="darkslategray2"), axis.text =element_text(color ="black", size =12), axis.title =element_text(color ="black", size =12), panel.grid.major.x =element_blank(), panel.grid.minor.x =element_blank(), panel.grid.major.y =element_line(color ="white"), panel.grid.minor.y =element_line(color ="white"), plot.caption =element_text(hjust =0))+scale_y_continuous(expand =expansion(mult =c(0, 0.1)))## Display the chartprint(chart)
With a good bar chart finished, it’s time to look more deeply into the data.
Prompt
I’d want to use the same data, but now treat each harvest as a replicate. Let’s test if there are statistically valid differences between the yield for the hedge and traditional plantings. I’m interested in both the means and variances. I’d like R code that does the tests and prints an interpretive statement regarding the results.
Response
Certainly! I’ll modify our R code to treat each harvest as a replicate and perform statistical tests to compare the yields between hedge and traditional plantings. We’ll conduct a t-test to compare means and an F-test to compare variances. Then, we’ll print interpretive statements for both tests.
This R code performs the following tasks:
It loads the necessary libraries and reads the previously saved data.
The data is reshaped into a long format for easier analysis.
Yields for hedge and traditional plantings are separated into two vectors.
A t-test is performed to compare the means of the two groups.
An F-test is performed to compare the variances of the two groups.
A helper function interpret_p_value() is defined to provide verbal interpretations of p-values.
The results of both tests are printed along with interpretive statements.
The interpretations are based on common statistical thresholds: - p < 0.01: strong evidence - 0.01 ≤ p < 0.05: moderate evidence - 0.05 ≤ p < 0.1: weak evidence - p ≥ 0.1: no significant evidence
This code provides a statistical analysis of the yield differences between hedge and traditional plantings, considering both the means and variances. The output includes numerical results (test statistics and p-values) as well as interpretive statements for easy understanding.
Would you like me to explain any part of this analysis in more detail or make any modifications to the code?
Show the code
## Load required librarieslibrary(tidyverse)library(readr)## Set read_csv function option to suppress warning messagesoptions(readr.show_col_types =FALSE)## Read the previously saved datadata<-read_csv("apple_tree_planting_data.csv")## Reshape the data for analysisdata_long<-data%>%pivot_longer(cols =starts_with("harvest"), names_to ="harvest", values_to ="yield")## Separate the yields for each planting methodhedge_yields<-data_long%>%filter(arrangement=="hedges")%>%pull(yield)traditional_yields<-data_long%>%filter(arrangement=="traditional")%>%pull(yield)## Perform t-test to compare meanst_test_result<-t.test(hedge_yields, traditional_yields)## Perform F-test to compare variancesf_test_result<-var.test(hedge_yields, traditional_yields)## Function to interpret p-valueinterpret_p_value<-function(p_value){if(p_value<0.01){return("strong evidence")}elseif(p_value<0.05){return("moderate evidence")}elseif(p_value<0.1){return("weak evidence")}else{return("no significant evidence")}}## Print results and interpretationscat("Statistical Analysis of Apple Tree Planting Yields\n")
Statistical Analysis of Apple Tree Planting Yields
cat("Interpretation: There is", interpret_p_value(t_test_result$p.value), "of a difference in mean yields between hedge and traditional plantings.\n\n")
Interpretation: There is no significant evidence of a difference in mean yields between hedge and traditional plantings.
Show the code
cat("2. Comparison of Yield Variances (F-test)\n")
cat("Interpretation: There is", interpret_p_value(f_test_result$p.value), "of a difference in yield variances between hedge and traditional plantings.\n")
Interpretation: There is no significant evidence of a difference in yield variances between hedge and traditional plantings.
Adding a Box Plot
Box plots are a useful visualization.
Prompt
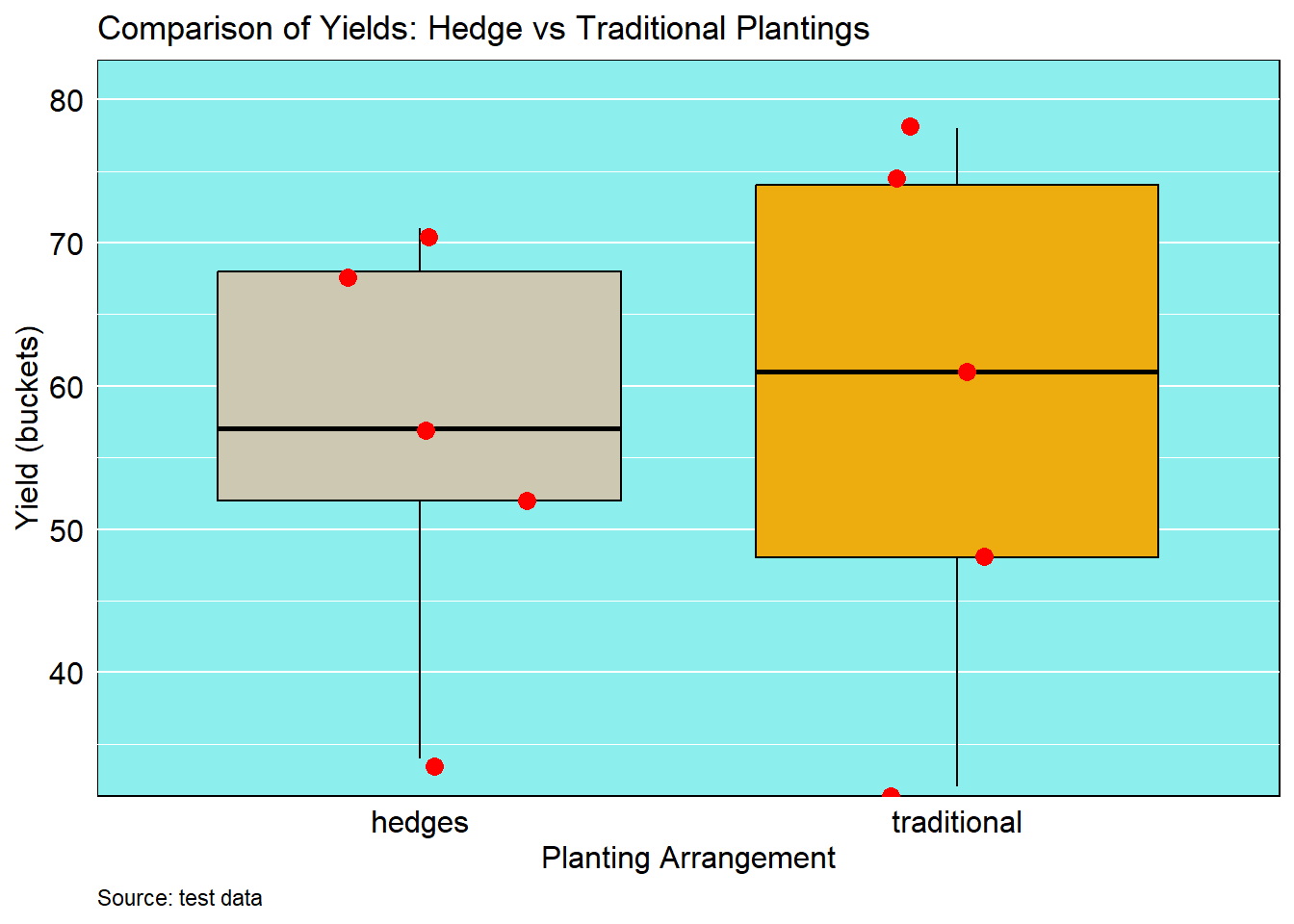
Now, can we use the same data file to see the data as a box plot comparing the two plantings?
Response
Certainly! I’ll create a box plot to visually compare the yield distributions of the hedge and traditional plantings using the same data file. This will provide a clear visual representation of the central tendencies, spread, and potential outliers in the data.
This R code does the following:
Loads necessary libraries and reads the previously saved data.
Reshapes the data into a long format suitable for ggplot2.
Creates a box plot using ggplot2 with the following features:
Boxes represent the interquartile range (IQR) for each planting arrangement.
The line inside each box represents the median.
Whiskers extend to the smallest and largest values within 1.5 times the IQR.
Individual data points are plotted as red dots (size 3) with slight jittering for better visibility.
Fill colors follow the guidelines: “cornsilk3” for hedges and “darkgoldenrod2” for traditional.
The panel background is set to “darkslategray2”.
Axis labels and title are in black, size 12.
Y-axis grid lines are white for better visibility on the dark background.
No X-axis grid lines are shown.
The source information is added as a caption.
Calculates and prints summary statistics for each planting arrangement.
This visualization adheres to the bar chart guidelines provided earlier, adapting them for a box plot. The box plot provides a clear visual comparison of the yield distributions between hedge and traditional plantings, showing the median, spread, and any potential outliers.
The summary statistics provide numerical context to complement the visual representation, giving a comprehensive view of the yield data for both planting arrangements.
Is there anything you’d like me to modify or explain further about this box plot visualization?
Show the code
## Load required librarieslibrary(tidyverse)library(readr)## Set read_csv function option to suppress warning messagesoptions(readr.show_col_types =FALSE)## Read the previously saved datadata<-read_csv("apple_tree_planting_data.csv")## Reshape the data for plottingdata_long<-data%>%pivot_longer(cols =starts_with("harvest"), names_to ="harvest", values_to ="yield")## Create the box plotboxplot<-ggplot(data_long, aes(x =arrangement, y =yield, fill =arrangement))+geom_boxplot(outlier.shape =NA, color ="black")+geom_jitter(color ="red", size =3, width =0.2)+scale_fill_manual(values =c("hedges"="cornsilk3", "traditional"="darkgoldenrod2"))+labs(title ="Comparison of Yields: Hedge vs Traditional Plantings", x ="Planting Arrangement", y ="Yield (buckets)", caption ="Source: test data")+theme_minimal()+theme( panel.background =element_rect(fill ="darkslategray2"), axis.text =element_text(color ="black", size =12), axis.title =element_text(color ="black", size =12), panel.grid.major.x =element_blank(), panel.grid.minor.x =element_blank(), panel.grid.major.y =element_line(color ="white"), panel.grid.minor.y =element_line(color ="white"), plot.caption =element_text(hjust =0), legend.position ="none")+scale_y_continuous(expand =expansion(mult =c(0, 0.1)))## Display the box plotprint(boxplot)
Show the code
## Calculate and print summary statisticssummary_stats<-data_long%>%group_by(arrangement)%>%summarize( Min =min(yield), Q1 =quantile(yield, 0.25), Median =median(yield), Mean =mean(yield), Q3 =quantile(yield, 0.75), Max =max(yield), SD =sd(yield))## Print summary statisticscat("\nSummary Statistics:\n")